玄武岩作为地幔部分熔融的产物,是研究地球深部过程的关键的地质记录。然而,如何准确识别玄武岩的地幔源区一直是科学家面临的挑战。在前人的研究中,通常使用同位素体系(如Sr-Nd-Pb)和微量元素判别图(如Zr/Nb vs. Nb/Th)来识别地幔端元。然而,随着岩石年龄的增加(特别是大于10亿年),传统判别图的分类区域出现显著重叠,更难以识别古老玄武岩的源区性质。为解决这一问题,中国科学院地质与地球物理研究所的蒋济莲博士,与Ross Mitchell研究员、彭澎研究员、王冲副研究员,以及邹心宇博后实现了玄武岩地幔源区的有效区分。
研究团队选取了新生代玄武岩(0-66 Ma)作为训练集,涵盖三种主要地幔源区:DM(亏损地幔源区)、EM(富集地幔源区)以及HM(含水地幔源区)。采用8种机器学习算法进行训练,DNN和SVM模型表现出最优性能(图1A),在测试集上准确率高达95%。在相同的测试集上,传统地球化学方法(以Zr/Nb vs. Nb/Th为例)仅只有36.09%的准确率,这表明机器学习相比传统指标显著提高了地幔源区识别准确率(图1B)。
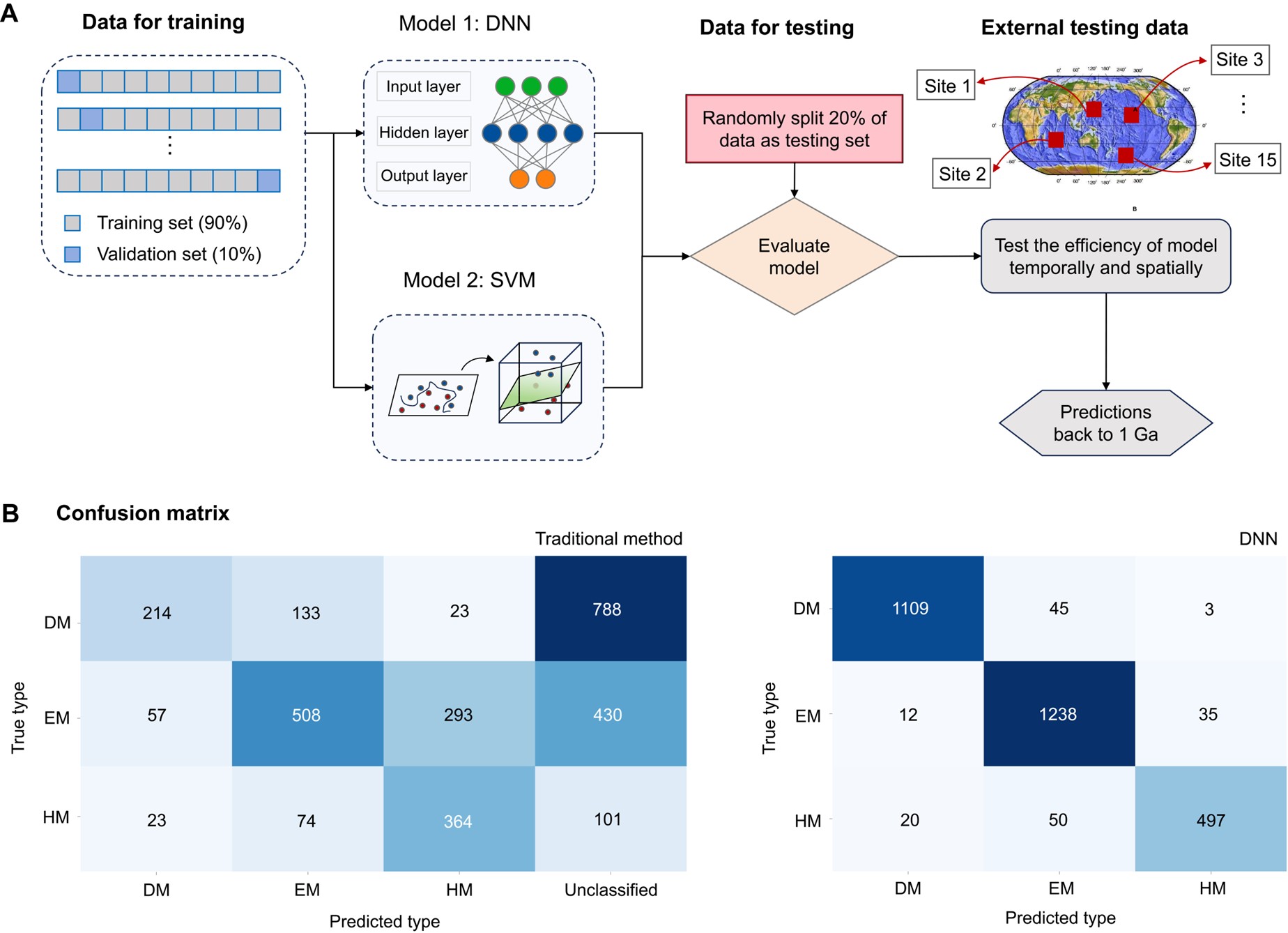
图1 机器学习方法的训练流程示意图及其与传统方法的效果对比
另外,还选取了15个全球典型地区作为独立测试集,时间跨度从新生代到约1.3Ga前。结果显示,模型对古老玄武岩的识别同样准确:约13亿年前的燕辽大火成岩省(EM源区)识别准确率达88%,约7.5亿年前的Wadi Ranga(HM源区)几乎全部样本被正确分类,约2.5亿年前的西伯利亚暗色岩(EM源区)准确率达92%(图2)。
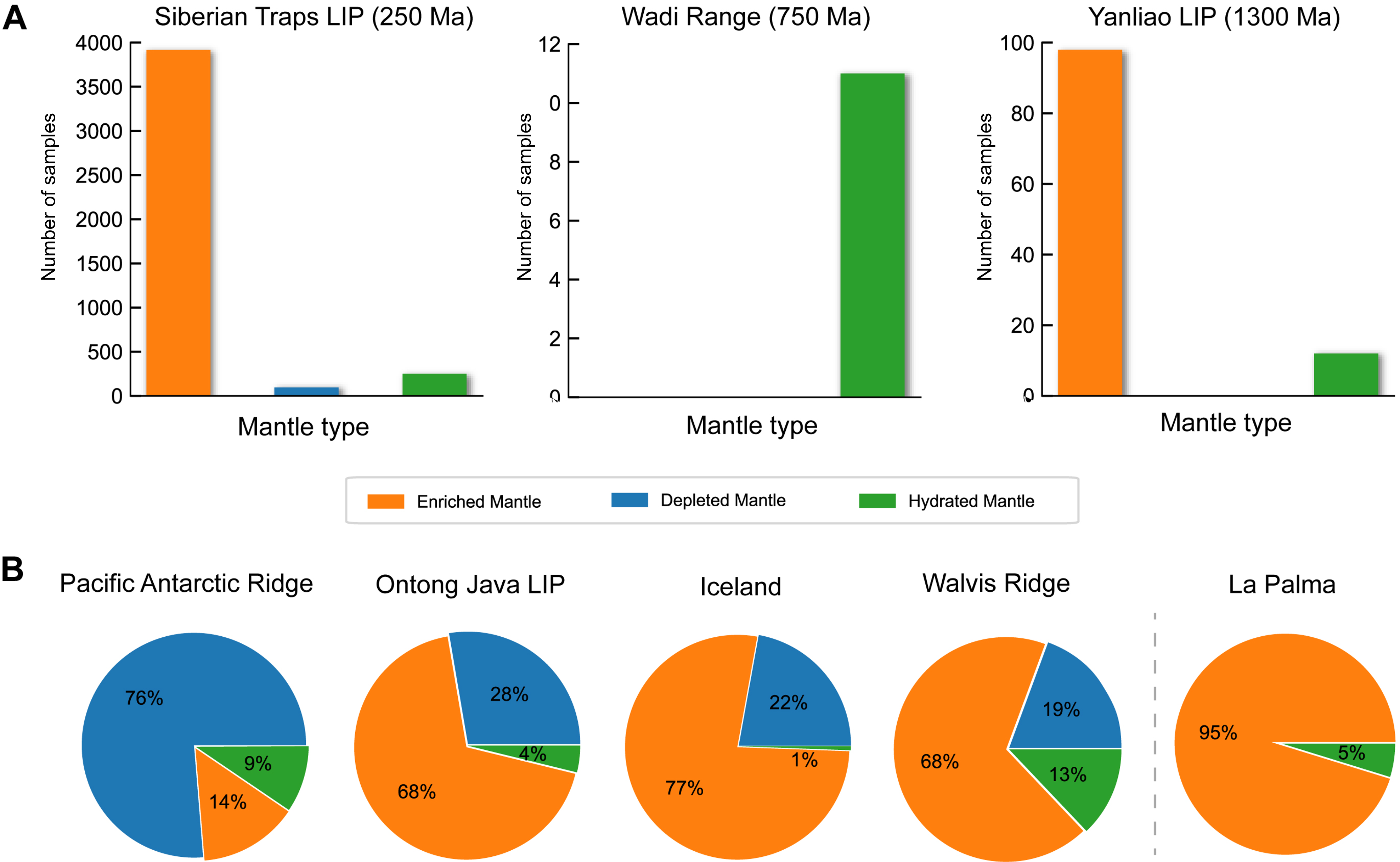
图2 玄武岩时间有效性验证以及在复杂岩浆构造环境的的预测结果
进一步将机器学习预测结果与全球全板块古地理重建模型进行对比,发现预测的地幔源区与重建的构造环境高度吻合。例如,100-200 Ma期间南美洲的EM组分与Paraná-Etendeka大火成岩省的位置一致,而HM样品则清晰地沿着板块边缘分布,对应着大陆和洋内弧的位置(如图3中浅蓝色条带)。
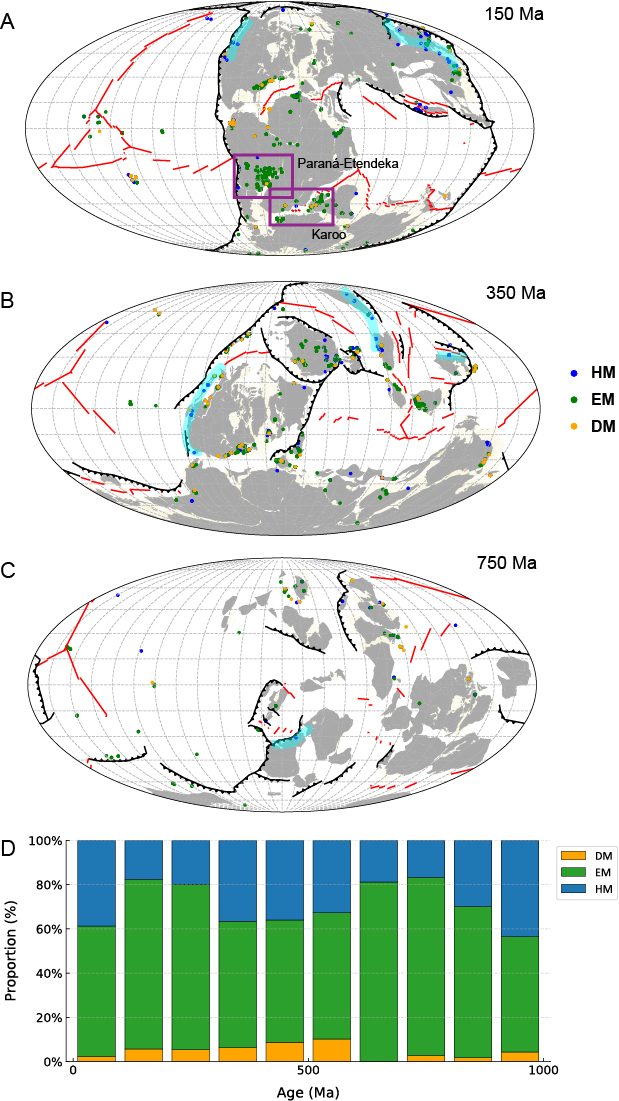
图3 0-1Ga的全球玄武岩的地幔源区分类古地理重建及其随时间的比例演化。三个时段(A) 100–200 Ma, (B) 200–500 Ma, and (C) 500–1000 Ma的玄武岩分布于分别重建于150、 250、750 Ma的古地理图上。浅蓝色条带突出显示HM类型玄武岩分布
研究还测试了模型在复杂构造-岩浆环境中的适用性。例如,Ontong Java高原的玄武岩显示出EM(68%)和DM(28%)的混合特征,与前人对此地区的地质认识一致;冰岛地区同时存在地幔柱和洋中脊岩浆作用,模型准确识别出77%的EM和22%的DM组分(图2)。
该研究不仅可以帮助我们追踪这些地幔储库在深时尺度上的时空演化,而且可以进一步为地幔不一致性的研究提供新视角和新的研究手段。
研究成果发表于国际学术期刊GRL(蒋济莲,Ross Mitchell*, 邹心宇,彭澎,王冲. Tracing mantle sources to tectono–magmatic settings: Machine learning classification of basalts over the past 1 billion years[J]. Geophysical Research Letters,2025. DOI: 10.1029/2025GL116461.)。该研究受中国科学院战略先导专项(B类)资助项目XDB0710000(R.N.M)以及中国科学院院长国际交流访问学者项目2021FYC0002(R.N.M;P.P)等资助。

蒋济莲(博士)